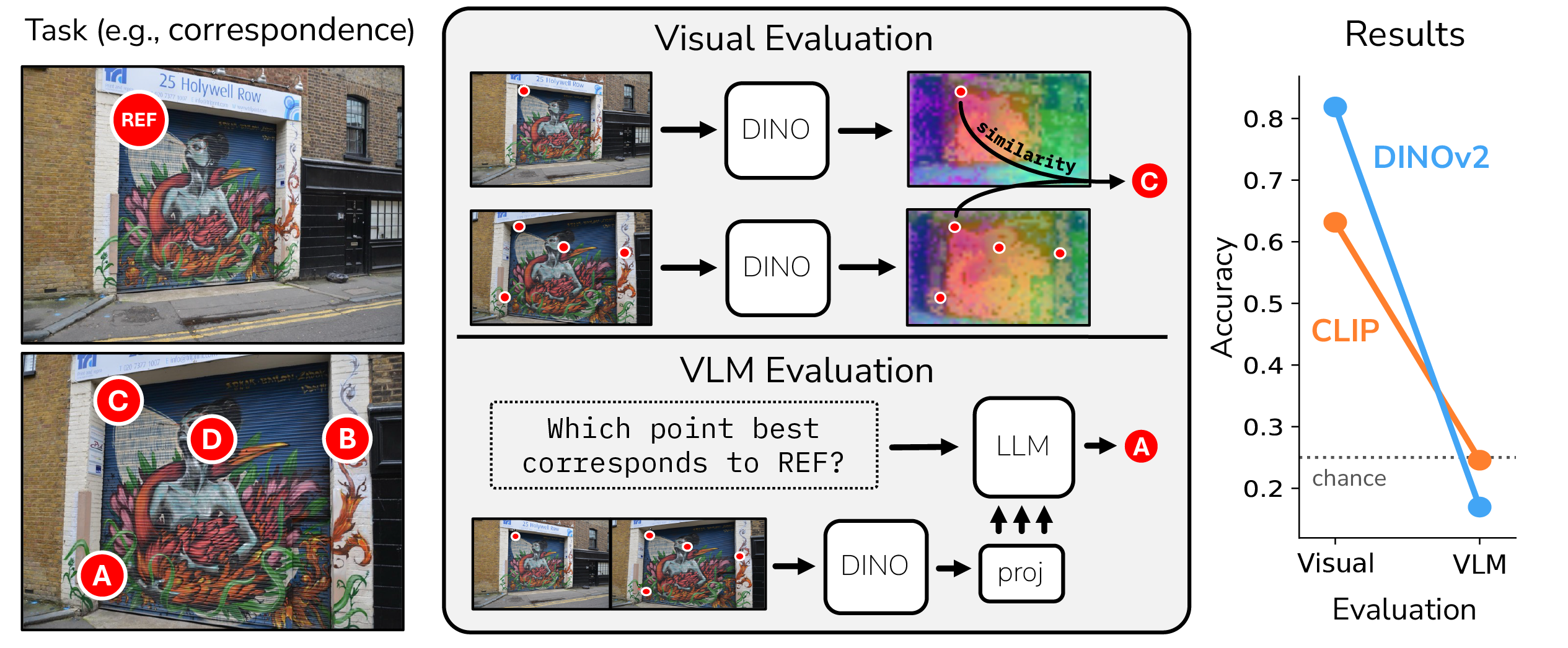
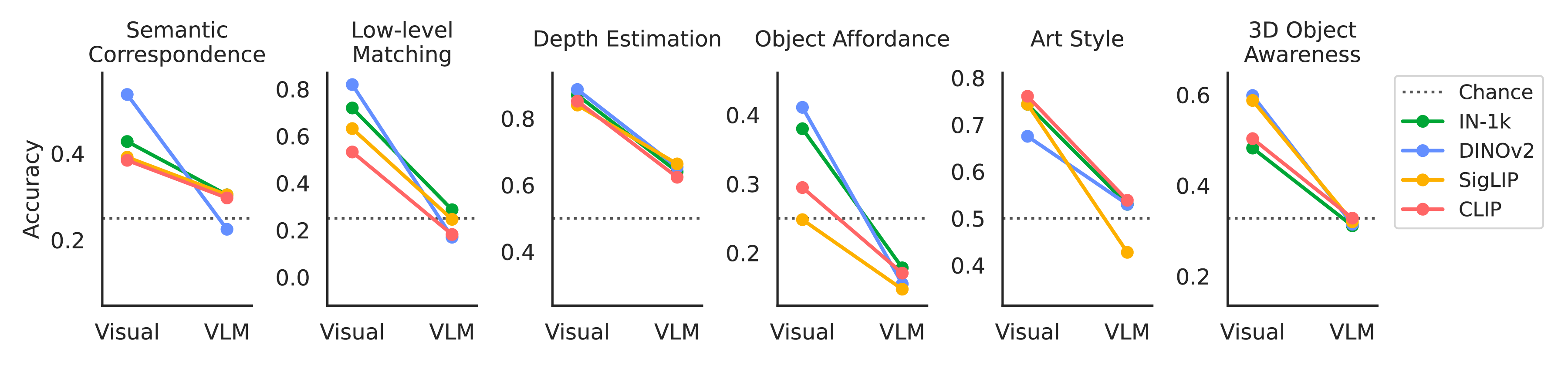
Language provides a natural interface to specify and evaluate performance on visual tasks. To realize this possibility, vision language models (VLMs) must successfully integrate visual and linguistic information. Our work compares VLMs to a direct readout of their visual encoders to understand their ability to integrate across these modalities. Across a series of vision-centric benchmarks (e.g., depth estimation, correspondence), we find that VLMs perform substantially worse than their visual encoders, dropping to near-chance performance. We investigate these results through a series of analyses across the entire VLM: namely 1) the degradation of vision representations, 2) brittleness to task prompt, and 3) the language model's role in solving the task. We find that the bottleneck in performing these vision-centric tasks lies in this third category; VLMs are not effectively using visual information easily accessible throughout the entire model, and they inherit their language biases. Our work helps diagnose the failure modes of open-source VLMs, and presents a series of evaluations useful for future investigations into visual understanding within VLMs.

Not exactly. Visual representations remain accessible and effective throughout the entire model, suggesting that the bottleneck lies in the language model's ability to utilize these representations rather than in their degradation across layers.

Prompt-tuning with prefix embeddings helps some, but is not the answer. We tune [1, 5, 10] prefix embeddings and compare results with the original performance (x=0) and visual evaluation ceiling (dotted line). We observe minimal returns that diminish after 1-5 prefix embeddings.

The LLM component is the primary bottleneck.
When fine-tuning each component of the VLM separately (vision encoder, projector, or LLM),
we find that fine-tuning the LLM 1) provides the most substantial improvements in performance;
2) best overcomes the language biases in outputting multiple choice answers; and 3) best improves attention over images;
suggesting that the VLM's performance bottleneck lies in the language model's ability to interpret visual representations.
@misc{fu2025hiddenplainsightvlms,
title={Hidden in plain sight: VLMs overlook their visual representations},
author={Stephanie Fu and Tyler Bonnen and Devin Guillory and Trevor Darrell},
year={2025},
eprint={2506.08008},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.08008},
}